Lookbook OpenAI & Pinecone Integration: Part III
Nov 23, 2025
After detailing the initial setup and requirements in the first two posts, we’re finally ready to dive into the main event: the AI integration.
Since I decided to use Pinecone for the vector database and OpenAI for the embeddings, the first step is to create API Keys. Setting up accounts for both of these platforms and generating API keys is straightforward. With Pinecone, you’ll create a serverless index and configure the dimension and cloud/rhavegion.
For this application, I configured the following:
- Model Embedding: `
text-embedding-3-small` as it's the most cost-efficient model from OpenAI. However, you can choose from a variety of models, including those from Nvidia, Cohere, and Microsoft, among others. - Dimension: 1536. The embedding model `
text-embedding-3-small`outputs vectors of size 1536, so the Pinecone index must use the same dimension.
Once these are generated, they cannot be changed, so choose wisely!
For Open AI, you'll need to create an account if you don't already have one. From there, you will need to add a balance to your account — something low like $5.00 should be sufficient for small text-based project. You can review their pricing and set limits as well as notifications.
Within your OpenAI account, you'll be able to create an API Key. Once generated, you'll save both the Pinecone and OpenAI Keys to your .env file.
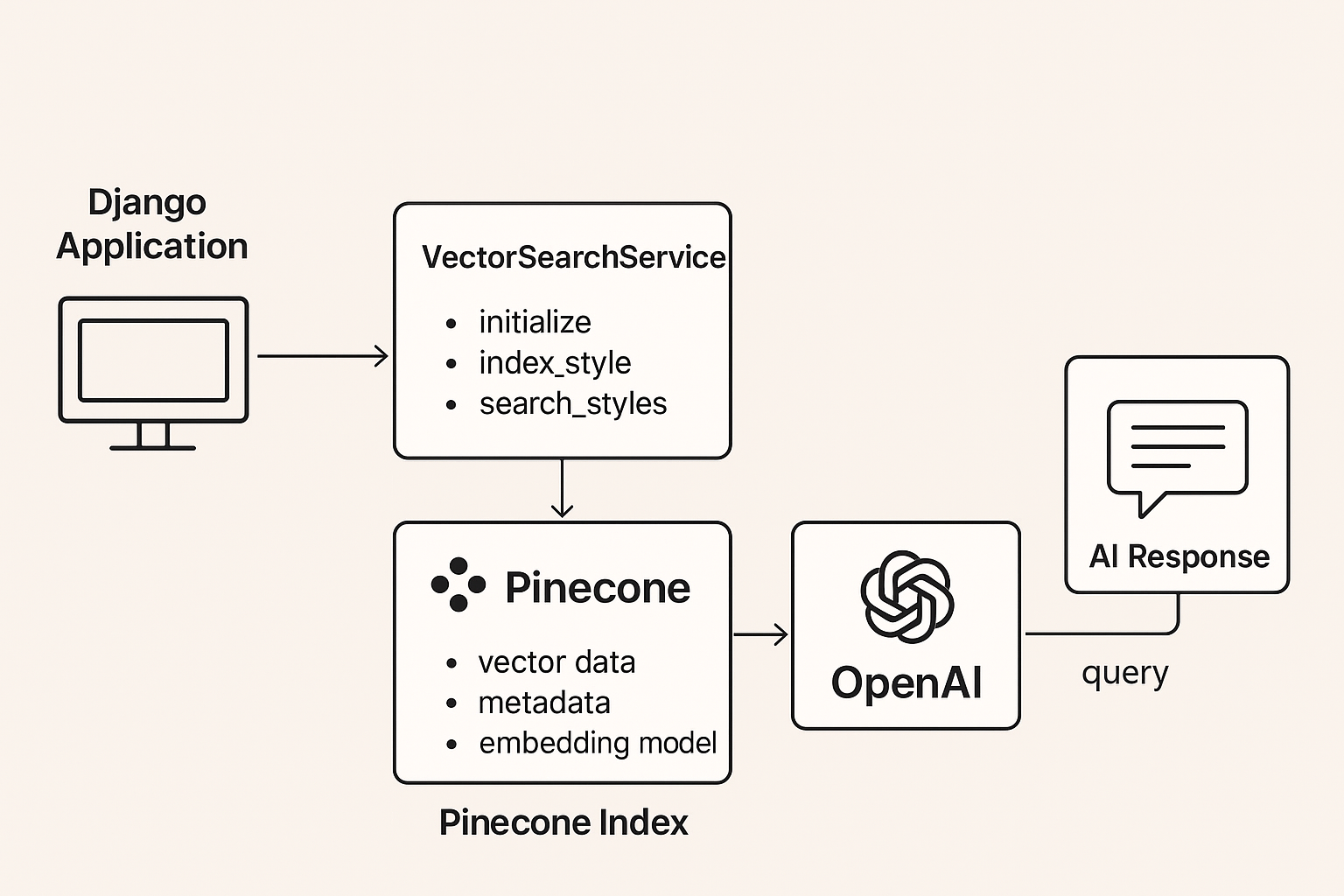
The Vector Search
Kiro became incredibly helpful with setting up code for creating the embeddings, indexing the search and querying the data. It created a VectorSearchService class within Django, which defined several functions. But what exactly is needed and how does it work?
Let’s take it step by step:
The initialization step
Within the `class VectorSearchService` lies the init function. As defined below, this is where the secrets are initialized to ensure we have access to all of the appropriate API calls. It grabs the API Keys for OpenAI and Pinecone, as well as the appropriate Pinecone DB name.

Next we need to index each of the styles so they are saved in Pinecone:

Walking through the code, you'll see that the first part involves calling the `create_style_text`. This looks for any of the Django tags and combines them. It then creates a list with each of the django model fields to ensure we get all of the possible text descriptions attached to each image.

From there, we need to call OpenAI to convert our text into actual embeddings that can be stored in our vector database. If you aren’t familiar, vector databases store a series of numbers. The model, in our case OpenAI, is required to convert the text-based data into appropriate embeddings needed for a vector-database.

Now we have an embedding that is used to match similar styles. The embedding is an array of numbers, similar to `[0.023, -0.891, 0.445, ...].` The metadata that we've defined isn't used to search for similarity, but rather to return info about the styles being returned. With both the embedding and the metadata defined, we can push this info to Pinecone using their `upsert` function.
With these functions established, we now have the code to convert our django text fields into embeddings for the vector database.
But how do we actually get these styles indexed so that hairstyles are appropriately updated in the database everytime a style is added, removed or modified? This is where Django Signals come in.
For our use case, we call the `index_style` function after every save within the Django admin.

Now, we've ensured that Pinecone is always up to date — perfect!
Query the Styles
Let's review what we've completed thus far:
- Text has been converted to embeddings — CHECK
- Embeddings are saved in Pinecone — CHECK
- The Database updates when styles are saved in Django — CHECK
How do we actually ensure the user is able to receive appropriate hair styles when they type in the chatbox? We query the styles!
In the initial setup, we generated an embedding whenever a new style was created in Django so it could be saved in Pinecone. Now, instead of generating an embedding for the styles saved in Django, we need to create an embedding based on the user input. So, if the user enters "I'm looking for a short, blonde hair style for women," we need this to be translated so our database can appropriately search this text.
We now query Pinecone by defining:
- Query embedding – the text the user searched for
- top_k — the number of top results to return. In our case, I've decided to return the top 10
- Include meta data — a boolean to indicate whether the metadata for each style should be returned
Lastly, we loop through each item returned and further filter the results by the score. The score is a value between 1 and 0 — the closer to 1 this number is, the more accurate the result.

The AI-Generated Response
Lastly, we want to get back an AI-generated response to go along with our styles. If you've used ChatGPT before, this part is similar to the text-based response that the chatbot returns to you. And, it's also where you can have a little fun defining the style in which you want the response to be returned.
Be creative with this part!

And that's it, folks!
Well, that's at least the most important aspects of turning your data into a searchable embedding. To check out the complete code, visit this repo.
There is a lot to explore within both the Pinecone and OpenAI documentation. But, if you're just getting your feet wet, like me, this should give you a starting point to get something up and running!
Next Up: The Final Reveal